7 Hidden Python Tips for 2024
Boost your work pace and advance your Python expertise



Python is one of the most widely used programming languages in the data science field. Its popularity just keeps on growing! The data science field itself has expanded tremendously in recent years. Today, everyone is talking about Machine Learning and Data Science. So it is a necessity to learn Python and Machine Learning. Let's take a look at some hidden Python tips.
In this article, we're excited to share seven tips that will not only improve your Python skills but also make you more productive. Discovering the right Python libraries can truly simplify your life! These tips will undoubtedly enhance your life as a Data Scientist or Data Engineer.
As a Data Scientist, have you ever found yourself grappling with complex formulas that need to be converted into LaTeX code, like when writing a paper? Well, the first tip is here to save your day! Let's dive in and see how it can make your life easier.
Stay curious!
Tip 1: Easily Convert an Image to LaTeX Code
Did you know there's this Python library called Pix2TeX that can magically transform images with equations into LaTeX code? Imagine how effortlessly you could integrate an equation from one document to another, without even needing to recreate it from scratch!
You can install the library using pip: pip install pix2tex[gui]
Let's look at an example.
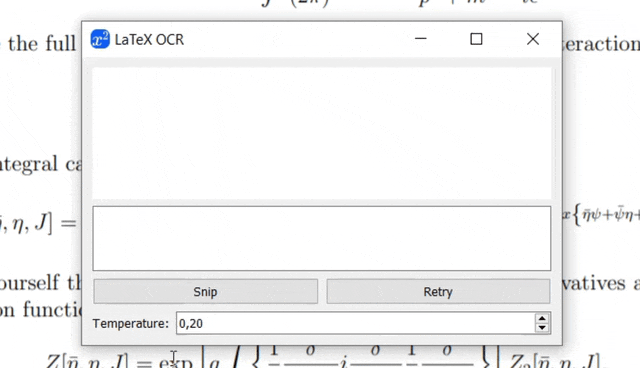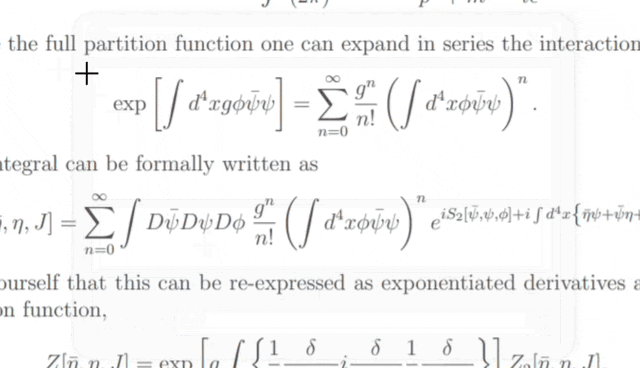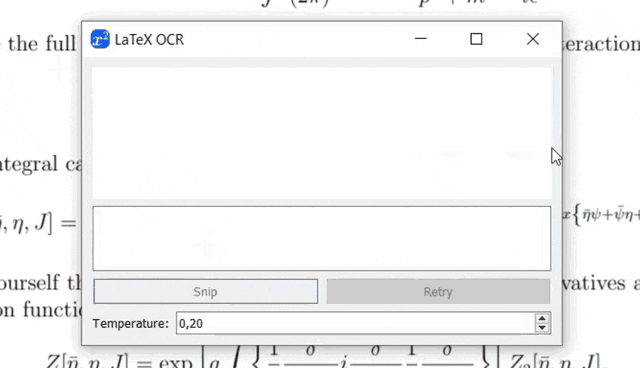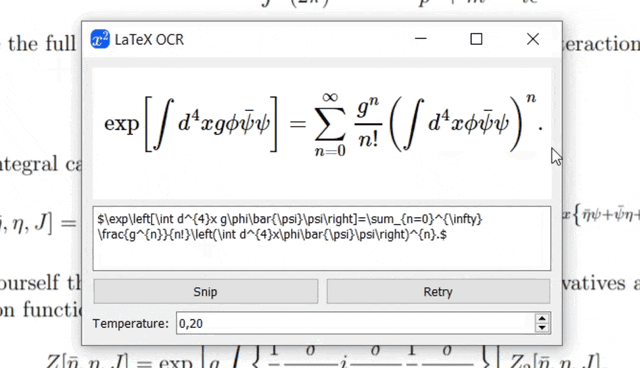
Gif by pix2tex
Wow, that's fascinating! Or what do you think? This package simplifies the writing of theses or scientific papers massively. And best of all, it's completely free.
Tip 2: Automatically remove unused Python code
This tip can make your source code more clean. As you know, there is a lot of unused code in large software projects. Unused Python code can cause several problems, such as:
Wasting memory and resources
Making it harder to understand the code
Challenges in testing and debugging of code
Curiously, there's a tool called vulture that can help you automatically remove unused Python code!
You can install the library using pip: pip install vulture
In the following, you can see an example:
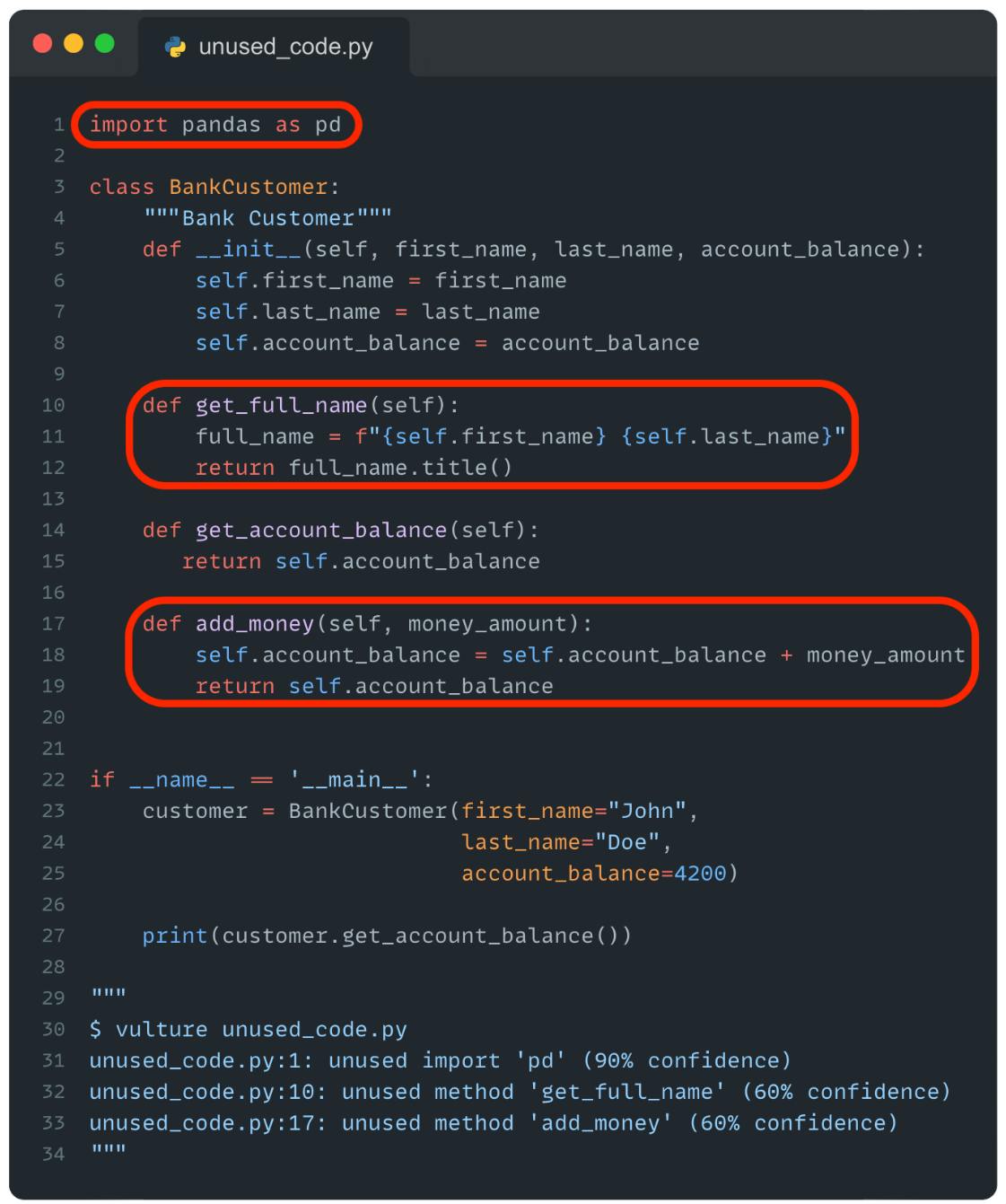
The code represents a bank customer. First, we import pandas and then we define the customer class. In the main, we create a customer object. Then, we output the customer's account balance.
After that, we ran our script with the package vulture. The tool returns all code sections that are not currently in use (marked in red). With this tool, you can clean up your code very easily.
Tip 3: Best Practices to Protect Sensitive Information
Another quick tip for you - it's always a smart idea to keep sensitive info in a .env file and then load it into your Python script with the help of the Python package python-dotenv.
This way, you can keep your important data safe from accidentally showing up in your codebase or version control systems.
You can install the library using pip: pip install python-dotenv
In the following, you can see how you can use the package.
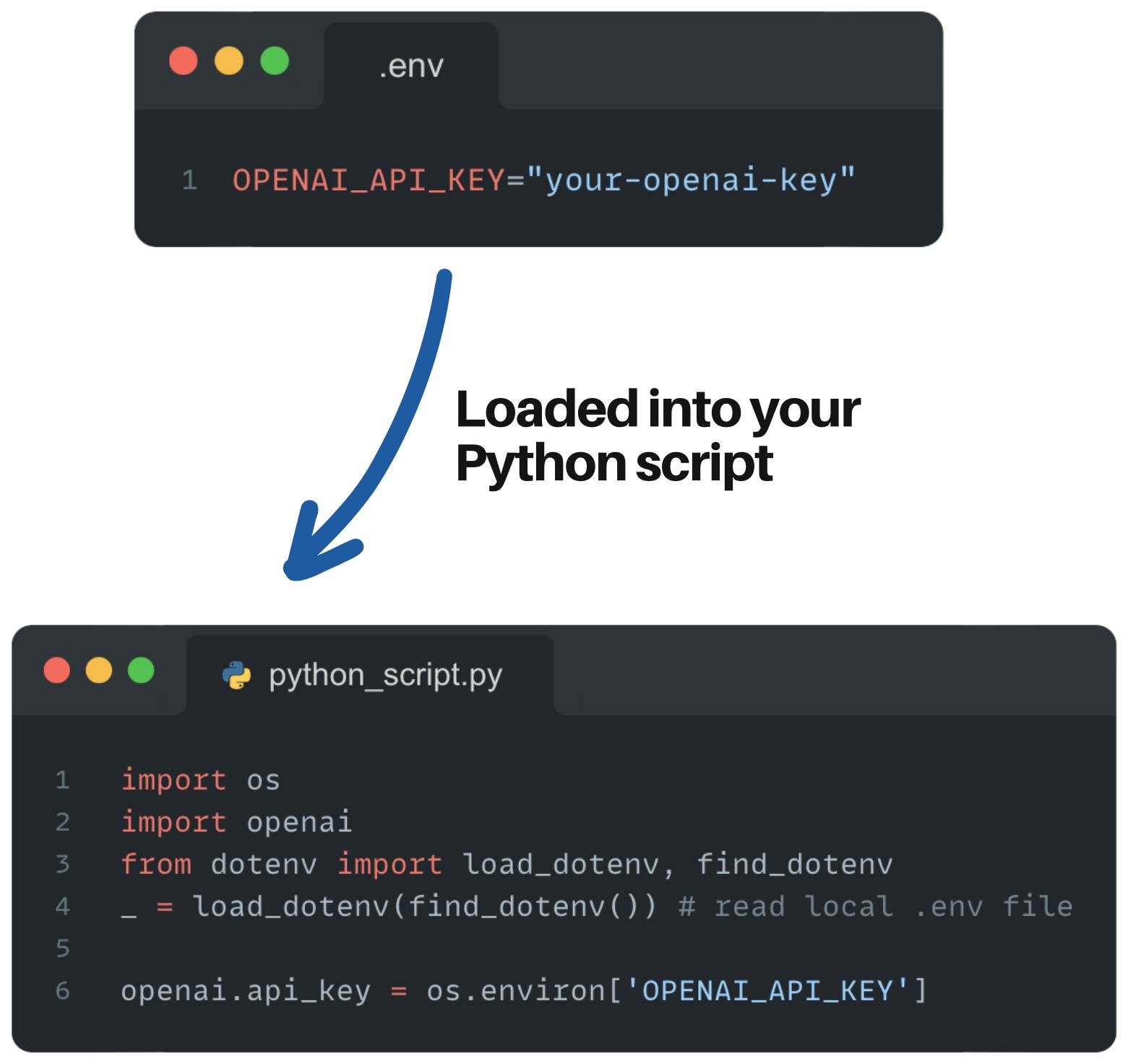
The code loads the OpenAI API key from a local .env file.
This procedure should be followed by all developers to avoid unnecessary costs caused by leaked information. Stay secure!
🎓 Our Online Courses and recommendations

Tip 4: Schedule Python Functions with Rocketry
To schedule Python functions with easy-to-understand and customizable scheduling statements, use Rocketry. Unlike other tools, Rocketry makes no assumptions about the project structure. It is excellent for fast and efficient automation projects.
You can install the library using pip: pip install rocketry
The following code shows how you can use the library.
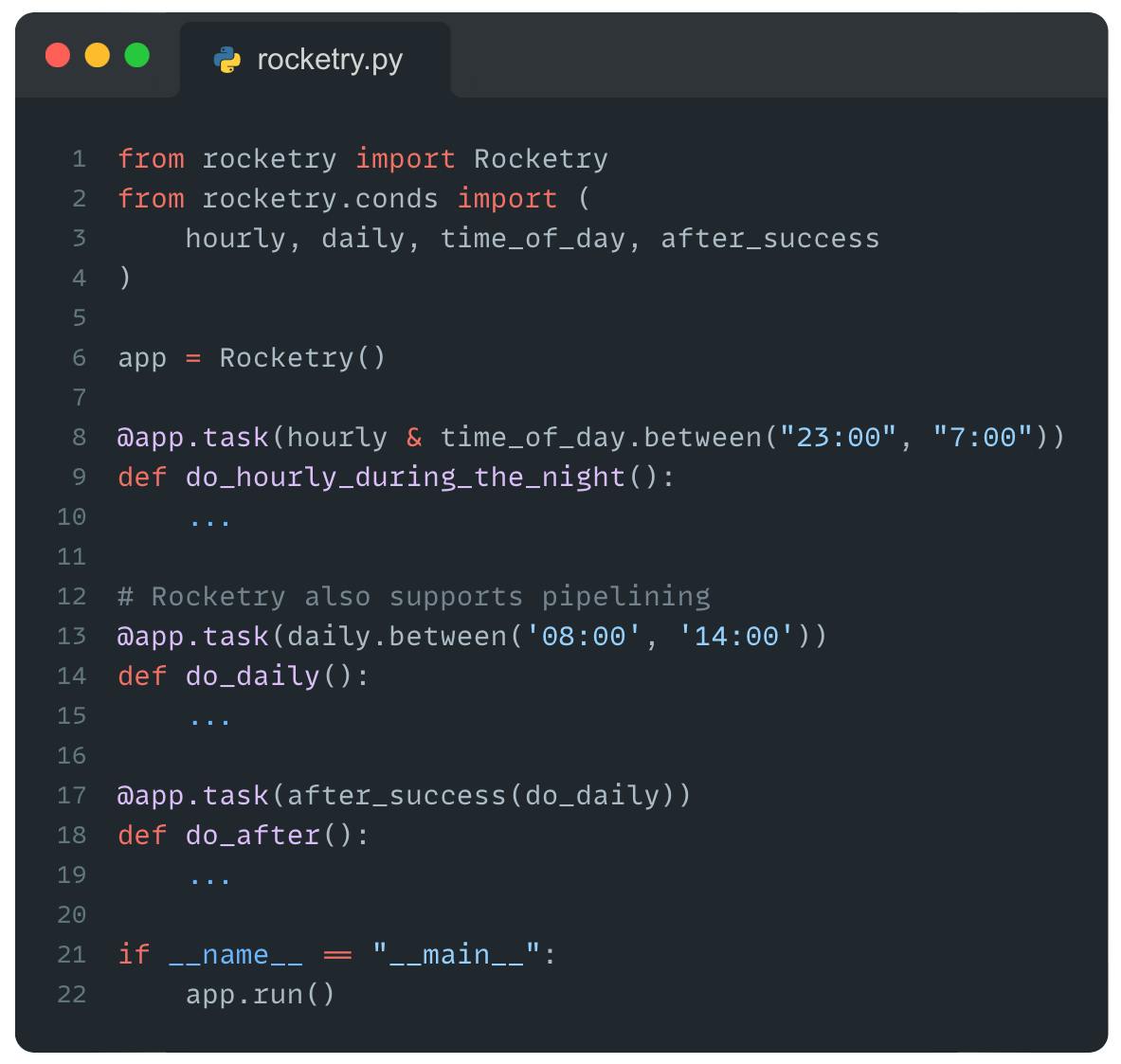
First, we import the package rocketry. Then, you can define tasks with the decorator @app.task(...) . Very easy or?
Tip 5: Generate Realistic Fake Data with Faker
Faker is a Python package that makes it easy to create fake but realistic data for testing. It can make names, addresses, zip codes, and more. Say goodbye to making test data by hand and improve your testing with Faker.
You can install the library using pip: pip install Faker
In the following, you can see some examples.
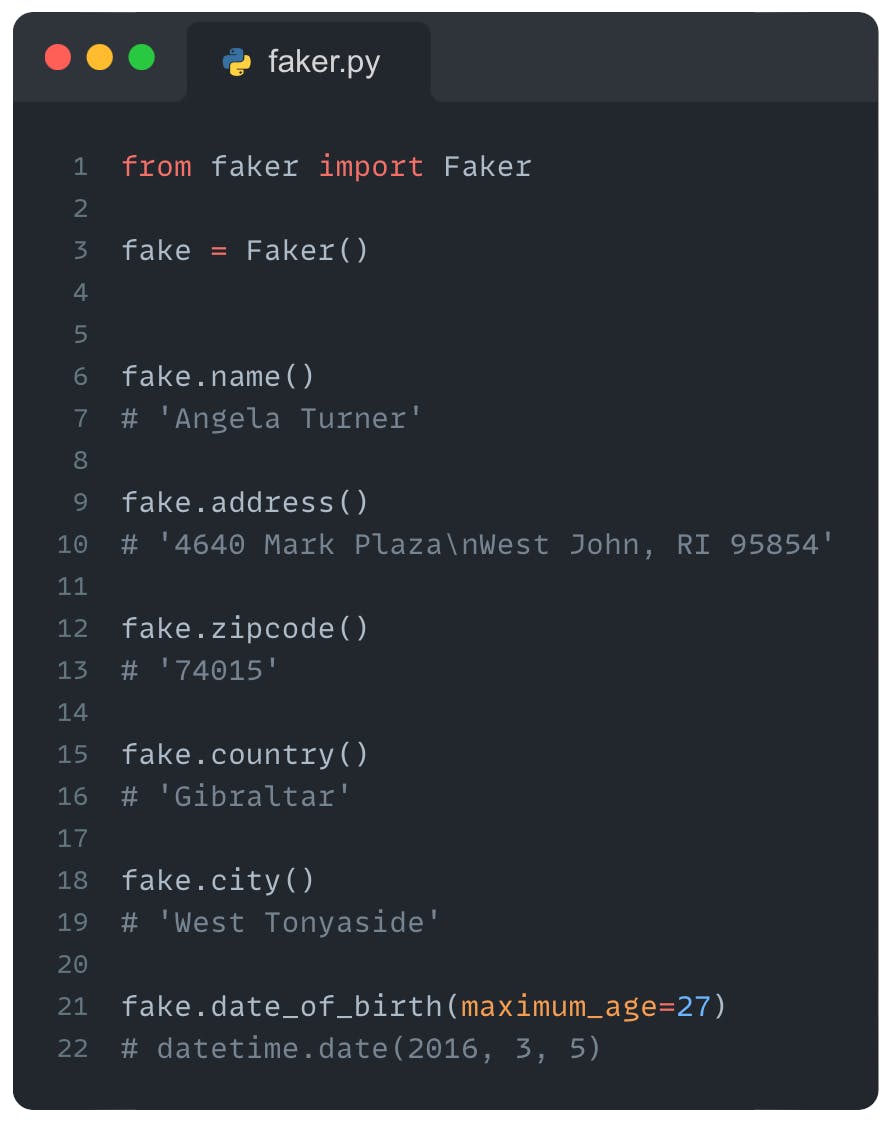
First, we import the package Faker and create an object. Then, you can use this object to generate realistic fake data (names, addresses, zipcodes and many more). Generating fake data is easier than ever before.
Tip 6: Tracking Your ML Experiments in an Easy Way
Tracking ML experiments is essential! But, you know that writing multiple log statements can be a bit of a hassle. To make things easier, you can add mlflow.autolog() before your training code for automatic logging.
And the best! We provide an open-source and docker-based MLflow Workspace to help you get started right away with tracking. You can download our MLflow Workspace from GitHub (Python examples included).
In the following, you can see a short demo video of how you can use our MLflow Workspace for automatic logging. You can find more information in the GitHub repo.
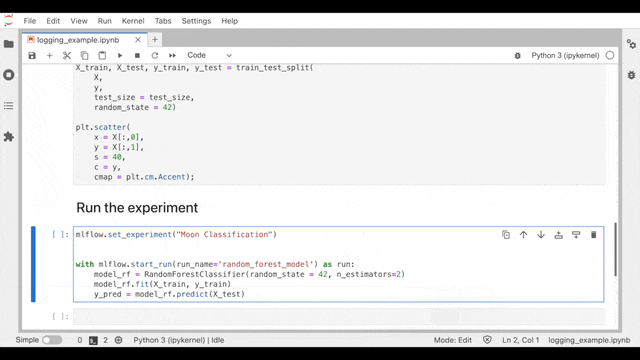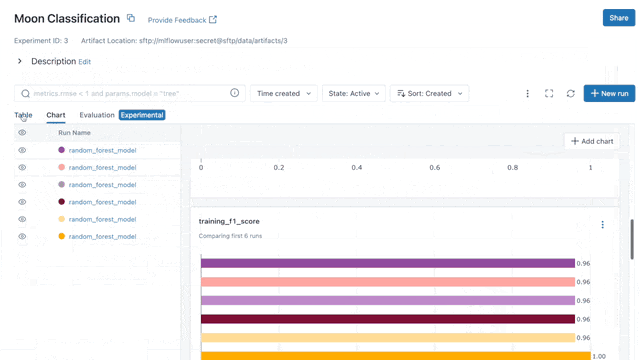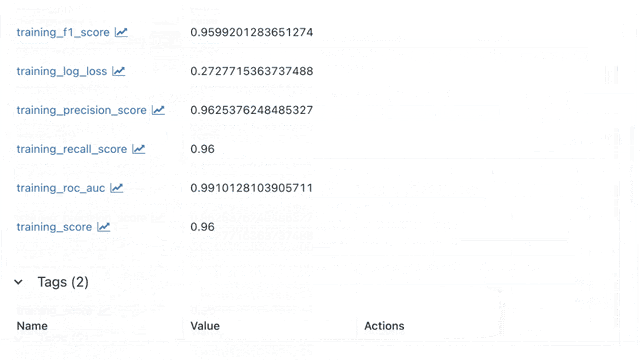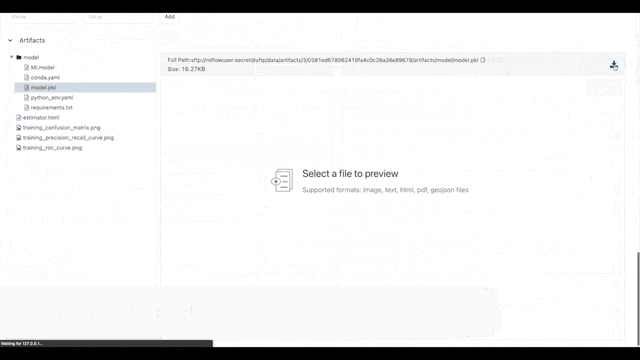
Have fun with the MLflow Workspace. Happy tracking!
Tip 7: Speed up Your Code with a Single Parameter
Large pandas dataframes can consume a large amount of memory. It's fascinating how processing data in smaller chunks can help prevent running out of memory and access data faster!
You can see an example in the figure.
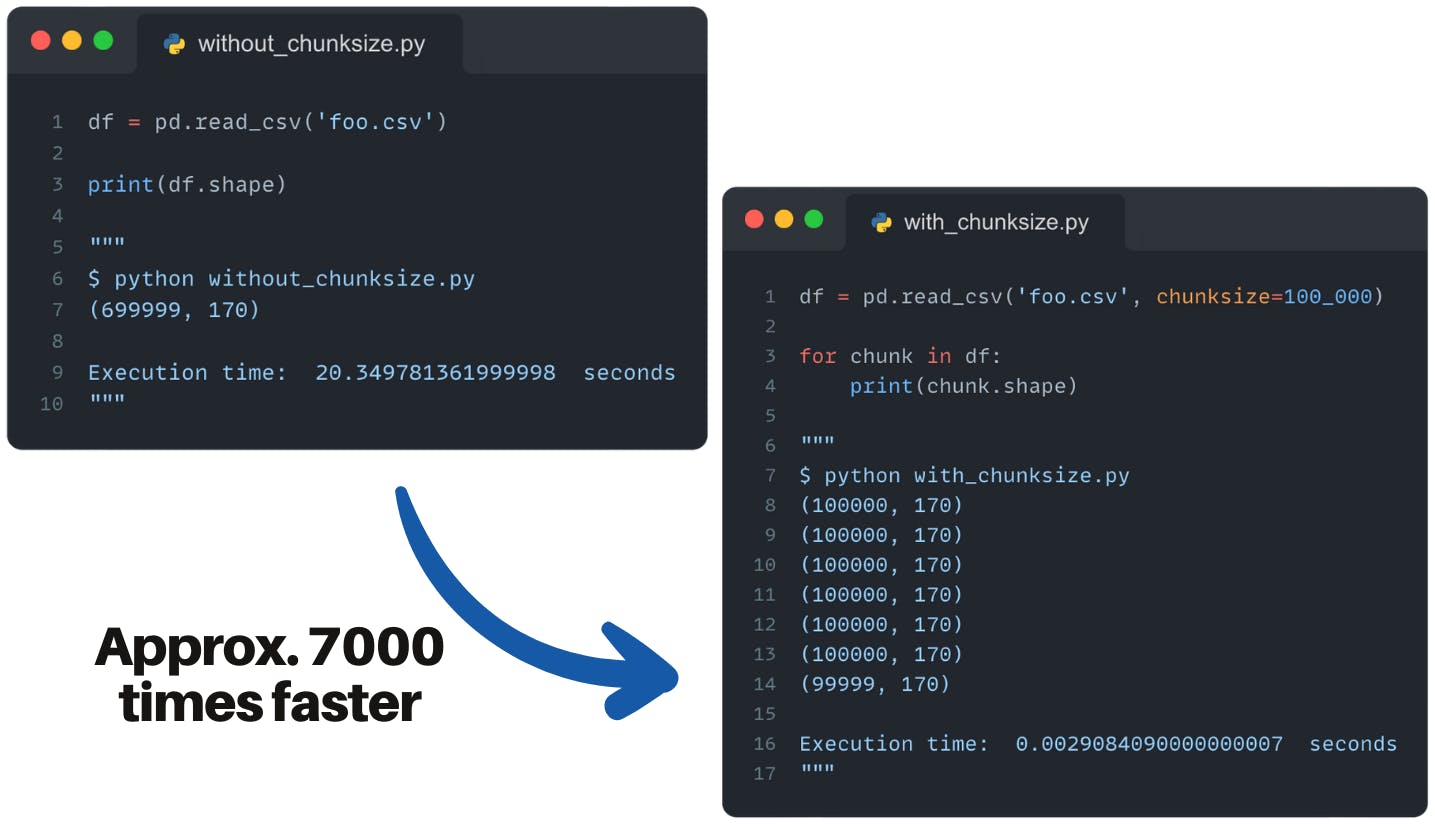
Wow, it's approximately 7000 times faster! The next time you want to read large dataframes, you should remember this parameter.
Conclusion
In conclusion, these seven tips are designed to elevate your Python skills, boost productivity, and simplify your life as a Data Scientist or Data Engineer.
From effortlessly converting images to LaTeX code with Pix2TeX, to cleaning up your code with vulture, protecting sensitive data with python-dotenv, scheduling functions with Rocketry, generating fake data with Faker, tracking ML experiments with mlflow, and speeding up your code while dealing with large pandas dataframes, each tip adds a unique value.
Embracing these tips will undoubtedly enhance your Python experience and your efficiency in the data science field. What's your favorite tip? Write your thoughts in the comments.
Thanks so much for reading. Have a great day!